 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOBD-Finder: Explainable Coarse-to-Fine Text-Centric Oracle Bone Duplicates Discovery
May 04, 2025



Oracle Bone Inscription (OBI) is the earliest systematic writing system in China, while the identification of Oracle Bone (OB) duplicates is a fundamental issue in OBI research. In this work, we design a progressive OB duplicate discovery framework that combines unsupervised low-level keypoints matching with high-level text-centric content-based matching to refine and rank the candidate OB duplicates with semantic awareness and interpretability. We compare our approach with state-of-the-art content-based image retrieval and image matching methods, showing that our approach yields comparable recall performance and the highest simplified mean reciprocal rank scores for both Top-5 and Top-15 retrieval results, and with significantly accelerated computation efficiency. We have discovered over 60 pairs of new OB duplicates in real-world deployment, which were missed by OBI researchers for decades. The models, video illustration and demonstration of this work are available at: https://github.com/cszhangLMU/OBD-Finder/.
Privacy-Preserving Federated Learning on Partitioned Attributes
Apr 29, 2021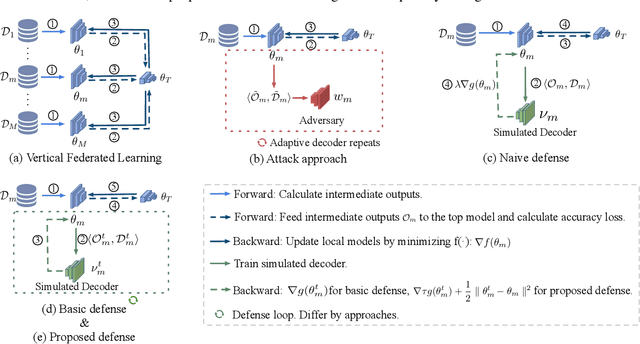

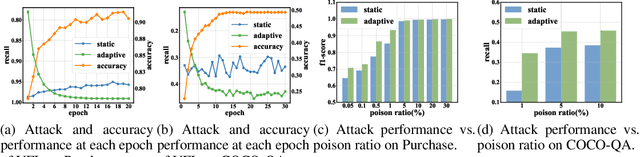
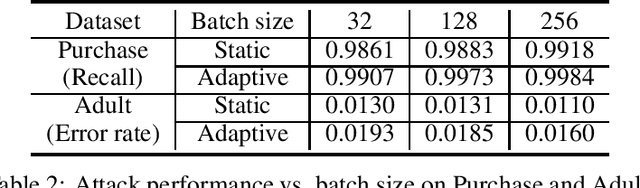
Real-world data is usually segmented by attributes and distributed across different parties. Federated learning empowers collaborative training without exposing local data or models. As we demonstrate through designed attacks, even with a small proportion of corrupted data, an adversary can accurately infer the input attributes. We introduce an adversarial learning based procedure which tunes a local model to release privacy-preserving intermediate representations. To alleviate the accuracy decline, we propose a defense method based on the forward-backward splitting algorithm, which respectively deals with the accuracy loss and privacy loss in the forward and backward gradient descent steps, achieving the two objectives simultaneously. Extensive experiments on a variety of datasets have shown that our defense significantly mitigates privacy leakage with negligible impact on the federated learning task.